Je bewerkt een video met meerdere sprekers, misschien een podcast of een interview. Handmatig ondertiteling toevoegen is vervelend:je moet elk gesproken woord beluisteren, typen en synchroniseren. Wat als uw video-editor automatisch verschillende stemmen zou kunnen herkennen en ondertiteling voor elke spreker zou kunnen genereren? Dat is waar sprekerherkenning in Python verandert het spel.
Python is de programmeertaal bij uitstek voor het ontwikkelen van spraakgebaseerde applicaties vanwege de robuuste bibliotheken. Deze bibliotheken helpen u bij het implementeren en inzetten van sprekerherkenningsmodellen voor realtime spraakverwerking, analyse en sprekeridentificatie. Pico Voice Eagle SDK levert bijvoorbeeld snelle en nauwkeurige luidsprekeridentificatie voor AI-gestuurde toepassingen.
Als alternatief zijn er videobewerkingsplatforms die kunstmatige intelligentie voor spraakherkenning integreren. Ze scannen de audio van de video, onderscheiden sprekers en genereren gesynchroniseerde ondertiteling.
In deze handleiding wordt onderzocht hoe u sprekeridentificatie in Python kunt implementeren. We zullen ook kijken naar de beste alternatieven zonder code voor moeiteloze video-ondertiteling.

In dit artikel
- Grondbeginselen van audioverwerking
- Realtime sprekeridentificatie met Picovoice Eagle SDK
- Zijn er eenvoudigere manieren om sprekerherkenning uit te voeren?
- Waar kan ik apps voor sprekerherkenning gebruiken?
Deel 1:Grondbeginselen van audioverwerking

Elk stemherkenningssysteem begint met audioverwerking. Geluid reist als continue analoge signalen, maar computers hebben digitale formaten nodig. Om spraak in gegevens om te zetten, gebruiken we bemonsteringsfrequenties en audiocoderingstechnieken.
Een samplingfrequentie bepaalt hoe vaak geluid per seconde wordt opgenomen. De standaard voor Python-luidsprekerherkenning is 16 kHz, wat een hoge nauwkeurigheid garandeert. Het formaat van het audiobestand is ook van belang:WAV, MP3 en FLAC zijn veelgebruikte opties, waarbij WAV de voorkeur heeft voor machine learning-taken.
Python vereenvoudigt realtime sprekeridentificatie met gespecialiseerde bibliotheken zoals PyAudio en Picovoice Eagle SDK. Met behulp van deze tools kunnen ontwikkelaars modellen vastleggen, analyseren en trainen voor realtime sprekeridentificatie in Python.
Deel 2:Realtime sprekeridentificatie met Picovoice Eagle SDK
Picovoice Eagle SDK is een krachtige tool voor sprekerherkenning in Python . In tegenstelling tot traditionele modellen verwerkt het audio lokaal. Deze SDK is cruciaal voor realtime sprekeridentificatie in Python, vooral in AI-beveiligingssystemen en slimme assistenten.
Bovendien is het lichtgewicht en werkt het naadloos op meerdere platforms, waaronder Windows, macOS, Linux, Android, iOS en zelfs Raspberry Pi. U hoeft zich alleen maar aan te melden voor de Pico Voice-console en uw toegangssleutel te verkrijgen om uw gebruik te verifiëren.
Pico Voice Eagle SDK installeren en instellen in Python
Als u de Picovoice Eagle SDK voor sprekerherkenning in Python wilt integreren, installeert u deze eerst. Voordat u dit doet, moet u ervoor zorgen dat Python 3.6+ is geïnstalleerd.
Open een terminal (Linux/macOS) of opdrachtprompt (Windows) en voer het volgende uit:
of
Als Python is geïnstalleerd, wordt er iets weergegeven als:
Als de versie 3.6 of hoger is, ben je klaar om te gaan.
Installeer om te beginnen de benodigde bibliotheken. Voer het volgende uit in uw terminal:
pip installeer Spraakherkenning pyaudio librosa pvrecorder
Voor Picovoice Eagle SDK, download en installeer:
pip installeer pvporcupine pveagle
Stapsgewijze handleiding voor het implementeren van realtime sprekeridentificatie met behulp van de Picovoice Eagle SDK in Python
- Stap 1:Installeer Python. Selecteer op de officiële Python-website de optie om de meest recente versie, Python 3. x.x. , te downloaden
- Stap 2:Meld u vervolgens aan voor een gratis Picovoice Console-account en haal uw toegangssleutel op. Deze sleutel is vereist om uw verzoeken te verifiëren bij gebruik van de Eagle Speaker Recognition SDK.
- Stap 3: Installeer de benodigde Python-pakketten. Voer de volgende opdracht uit in uw terminal:
pip installeer pveagle pvrecorder
Hiermee installeer je PV Eagle (voor sprekerherkenning) en PV Recorder (voor audio-opname).
- Stap 4: Maak twee bestanden in uw VsCode. Het eerste bestand is het inschrijven van een spreker. Inschrijving is het proces waarbij een sprekerprofiel wordt aangemaakt op basis van stemgegevens. Volg deze stappen:
- Importeer de vereiste bibliotheken
- Initialiseer EagleProfile met uw toegangssleutel
- Gebruik PV Recorder om stemvoorbeelden vast te leggen
- Voed audioframes toe aan EagleProfile totdat de inschrijving is voltooid
- Exporteer het sprekerprofiel voor toekomstige herkenning
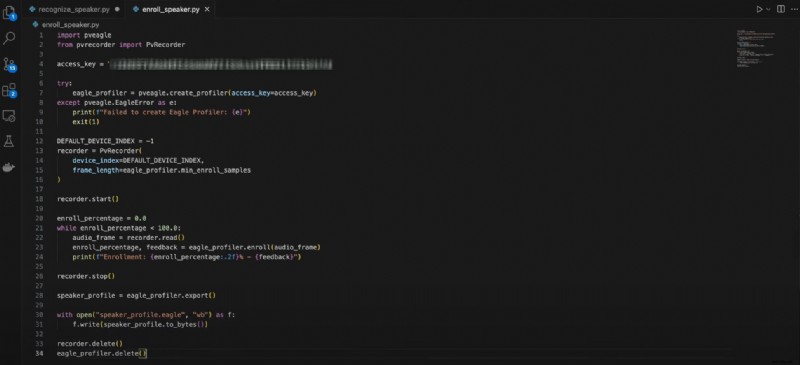
Hier is de code voor de inschrijving van sprekers:
importeer pveaglevan pvrecorder importeer PvRecorder
access_key ="UW_ACCESS_KEY"
probeer:
eagle_profiler =pveagle.create_profiler(toegangssleutel=toegangssleutel)
behalve pveagle.EagleError als e:
print(f"Kan Eagle Profiler niet maken:{e}")
uitgang(1)
DEFAULT_DEVICE_INDEX =-1
recorder =PvRecorder(
device_index=DEFAULT_DEVICE_INDEX,
frame_length=eagle_profiler.min_enroll_samples
)
recorder.start()
inschrijvingspercentage =0,0
terwijl inschrijvingspercentage <100,0:
audio_frame =recorder.lezen()
inschrijven_percentage, feedback =eagle_profiler.enroll(audio_frame)
print(f"Inschrijving:{enroll_percentage:.2f}% - {feedback}")
recorder.stop()
speaker_profile =eagle_profiler.export()
met open("speaker_profile.eagle", "wb") als f:
f.write(speaker_profile.to_bytes())
recorder.delete()
eagle_profiler.delete()
- Stap 5:Ga naar uw terminal en neem op door de onderstaande code in te voeren
python3 enroll_speaker.py
Zodra het script wordt uitgevoerd, probeert u in de microfoon te spreken. Als uw stem overeenkomt met het geregistreerde sprekerprofiel, wordt er 'Speaker herkend!' weergegeven. Anders wordt er een onbekende spreker aangegeven.

- Stap 6: Nu het sprekerprofiel klaar is, gaan we een code maken voor realtime sprekerherkenning in het tweede bestand. Hierdoor wordt een sprekerprofiel geladen en wordt een spreker in realtime herkend met behulp van de Pico Voice Eagle SDK.
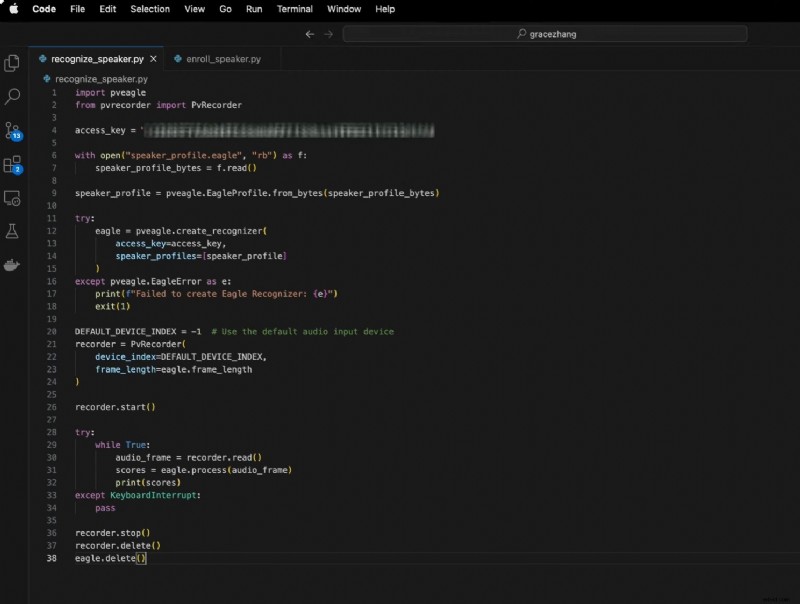
Het gaat hierbij om:
- Een Eagle-instantie maken met uw toegangssleutel en luidsprekerprofiel
- PV-recorder gebruiken om live audio vast te leggen
- De audioframes doorgeven aan Eagle voor realtime herkenning
Hier is de code:
pveagle importerenvanuit pvrecorder importeer PvRecorder
access_key ="UW_ACCESS_KEY"
met open("speaker_profile.eagle", "rb") als f:
speaker_profile_bytes =f.read()
speaker_profile =pveagle.EagleProfile.from_bytes(speaker_profile_bytes)
probeer:
adelaar =pveagle.create_recognizer(
toegangssleutel=toegangssleutel,
speaker_profiles=[speaker_profile]
)
behalve pveagle.EagleError als e:
print(f"Kan Eagle Recognizer niet aanmaken:{e}")
uitgang(1)
DEFAULT_DEVICE_INDEX =-1 # Gebruik het standaard audio-invoerapparaat
recorder =PvRecorder(
device_index=DEFAULT_DEVICE_INDEX,
frame_length=adelaar.frame_lengte
)
recorder.start()
probeer:
terwijl waar:
audio_frame =recorder.lezen()
scores =adelaar.process(audio_frame)
afdrukken(partituren)
behalve KeyboardInterrupt:
passeren
recorder.stop()
recorder.delete()
eagle.delete()
- Stap 7:Test en voer de applicatie uit.
Python3 recognize_speaker.py
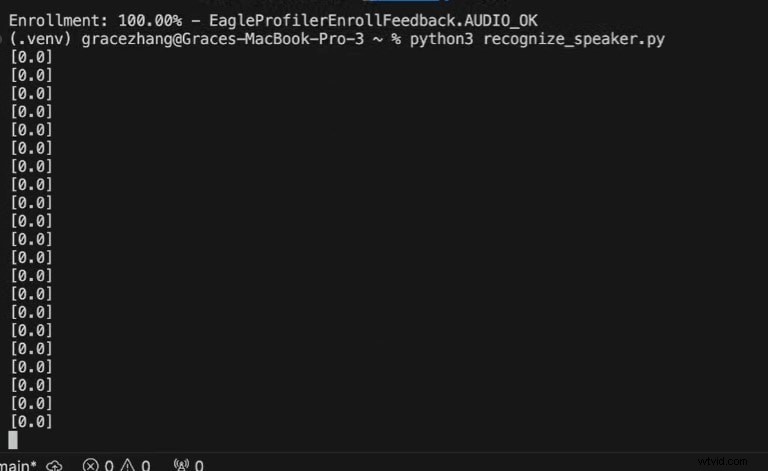
0 =Stem niet herkend
1 =Stem herkend

Opmerking:In tegenstelling tot cloudgebaseerde modellen verwerkt Picovoice Eagle SDK gegevens lokaal. Dit zorgt voor snellere resultaten, betere privacy en geen internetafhankelijkheid.
Luidsprekeridentificatie in Python kan alleen worden begrepen en uitgevoerd door professionele programmeurs. Je moet enige kennis van programmeren hebben om het proces te begrijpen.
Deel 3:Zijn er eenvoudigere manieren om sprekerherkenning uit te voeren?
Voor het bouwen van een Python-sprekerherkenningssysteem zijn codeervaardigheden en technische kennis vereist. Hoewel identificatie in Python krachtig is, kan het een uitdaging zijn voor niet-programmeurs. Veel gebruikers geven de voorkeur aan kant-en-klare tools die vergelijkbare spreker- en spraakherkenningsfuncties bieden. Het is een betere manier om de taak uit te voeren zonder codeervaardigheden.
Een voorbeeld van zo'n tool is WondershareFilmora, een video-editor met ingebouwde sprekerherkenning en spraakbewerking. Hiermee kunnen gebruikers spraakopnamen detecteren, transcriberen en wijzigen zonder ook maar één regel code te schrijven.
In tegenstelling tot Python-luidsprekerherkenning, waarvoor handmatige modeltraining nodig is, automatiseren de ingebouwde tools van Filmora het proces. U kunt audiobestanden bewerken en verbeteren zonder kennis van Python of machine learning. Dit maakt sprekeridentificatie toegankelijk voor makers van inhoud, marketeers en zakelijke gebruikers.
Filmora's functies voor mobiele luidsprekerdetectie en spraakbewerking
Filmora integreert een AI-aangedreven tool die audiobewerking en sprekerherkenning vereenvoudigt. Met de mobiele versie hebben gebruikers toegang tot functies voor sprekerdetectie en spraakbewerking.
- Luidsprekerdetectie. Luidsprekerdetectie analyseert audio en maakt onderscheid tussen verschillende luidsprekers. In plaats van de handmatige manier van luisteren en stemmen taggen, identificeert de AI wie wanneer spreekt.
- Spraakbewerking. Het bewerken van spraak kan vervelend zijn, maar Spraakbewerking van Filmora vereenvoudigt het proces. Hiermee kunnen gebruikers stemopnames wijzigen, de helderheid aanpassen en achtergrondgeluiden verwijderen.
Stem herkennen, converteren naar tekst en bewerken met Filmora onderweg
Filmora maakt sprekerherkenning eenvoudig met een paar klikken. Hier is een stapsgewijze handleiding:
- Stap 1:Download Filmora, klik op 'nieuw project' en importeer de video met stem.
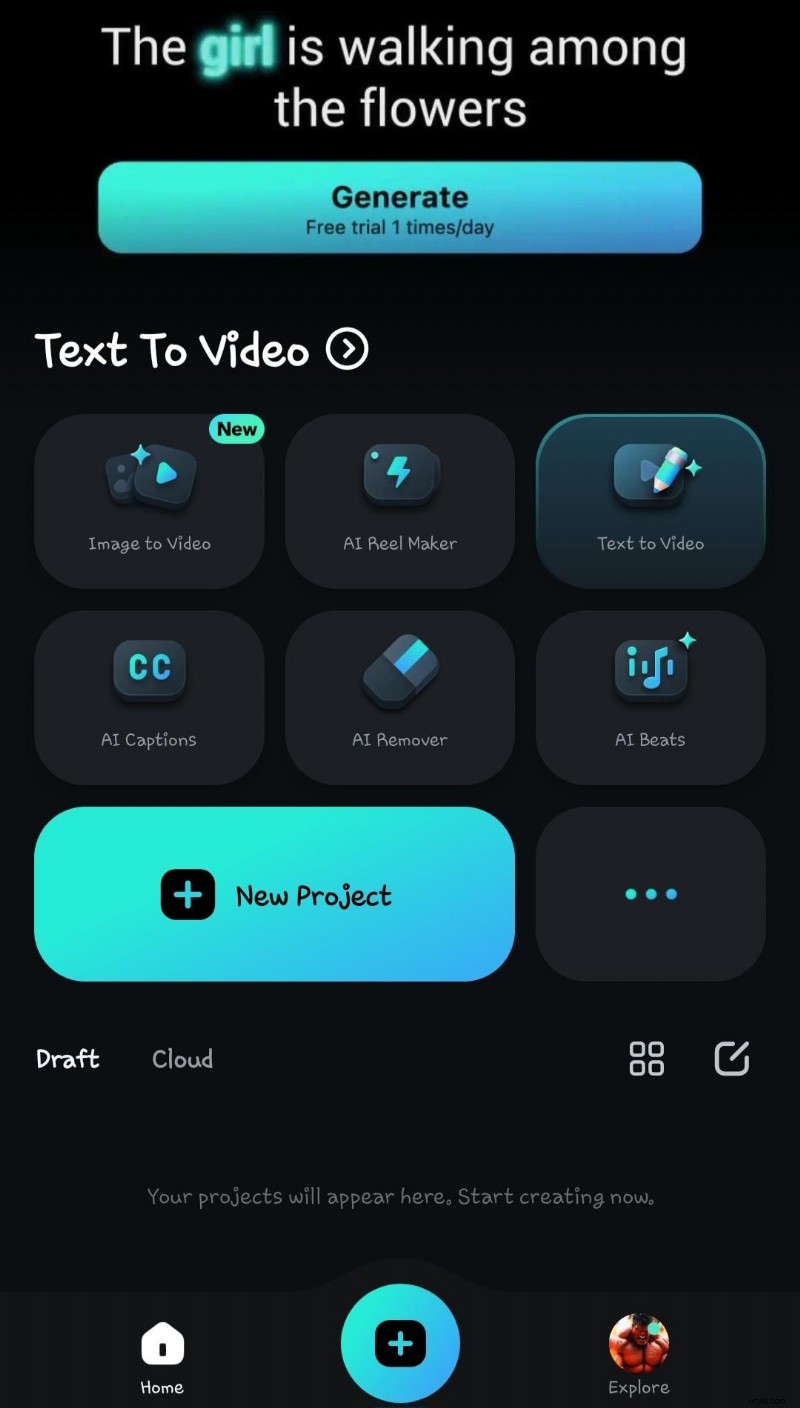
- Stap 2:Selecteer tekst om de gesproken woorden om te zetten in tekst.

- Stap 3:klik op AI-ondertiteling om het stemherkenningsproces te starten
- Stap 4: Klik op de optie Luidsprekerdetectie voordat u Ondertiteling toevoegen selecteert
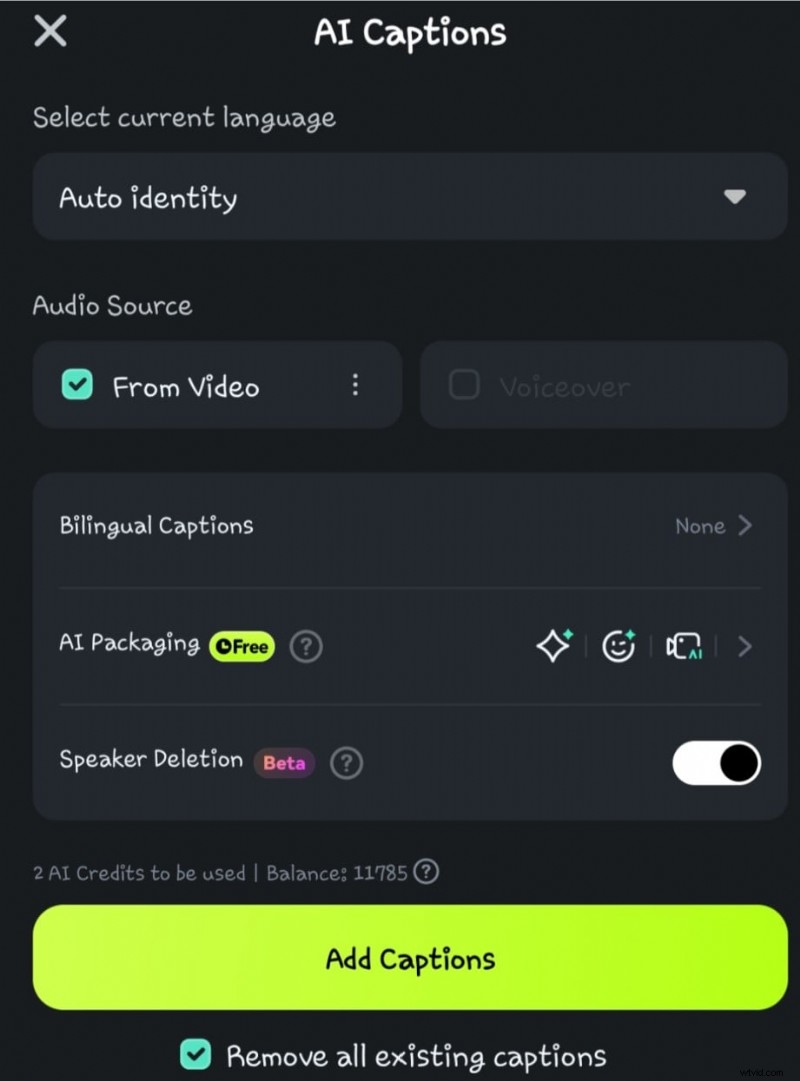
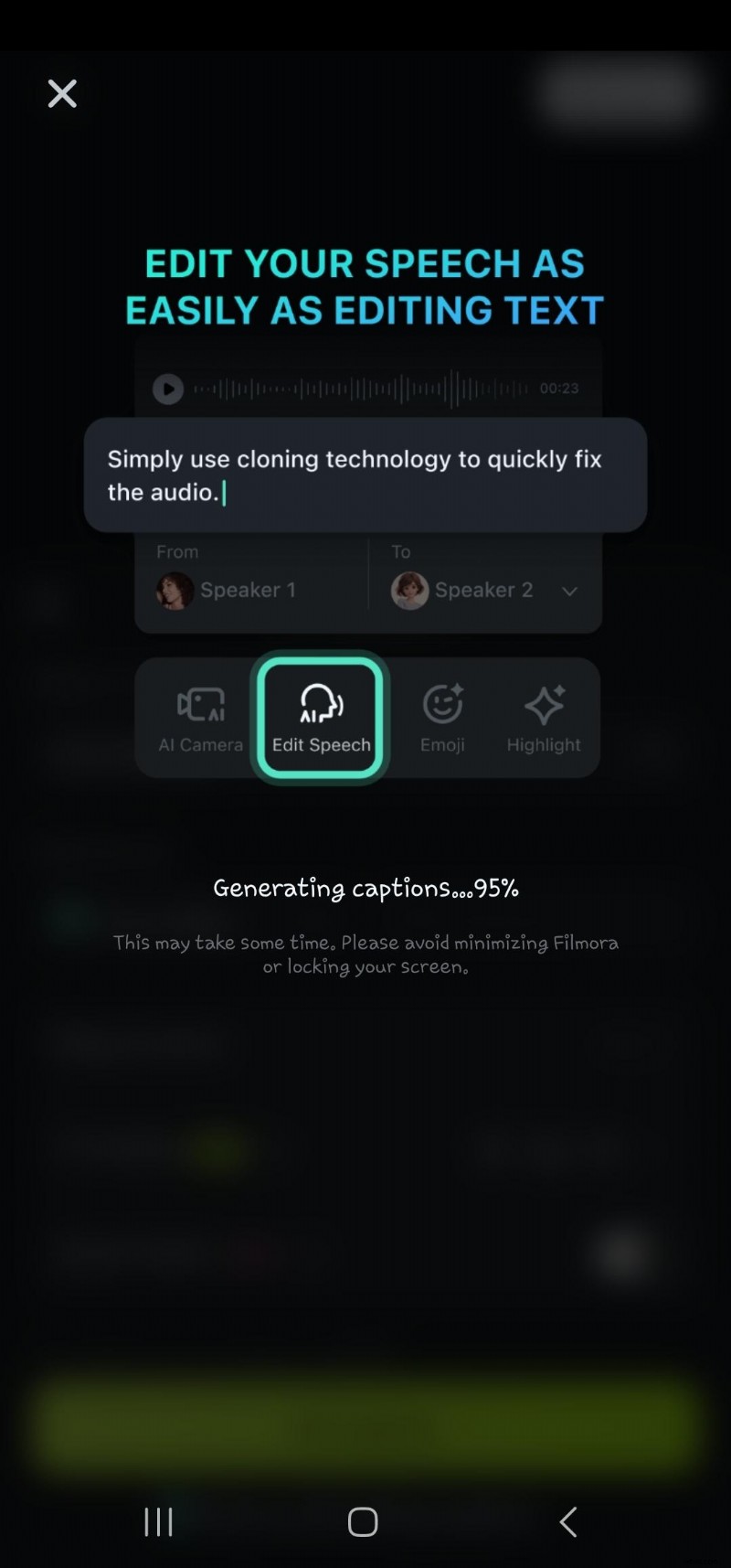
- Stap 5: Wacht terwijl de AI de spraak-naar-tekst verwerkt
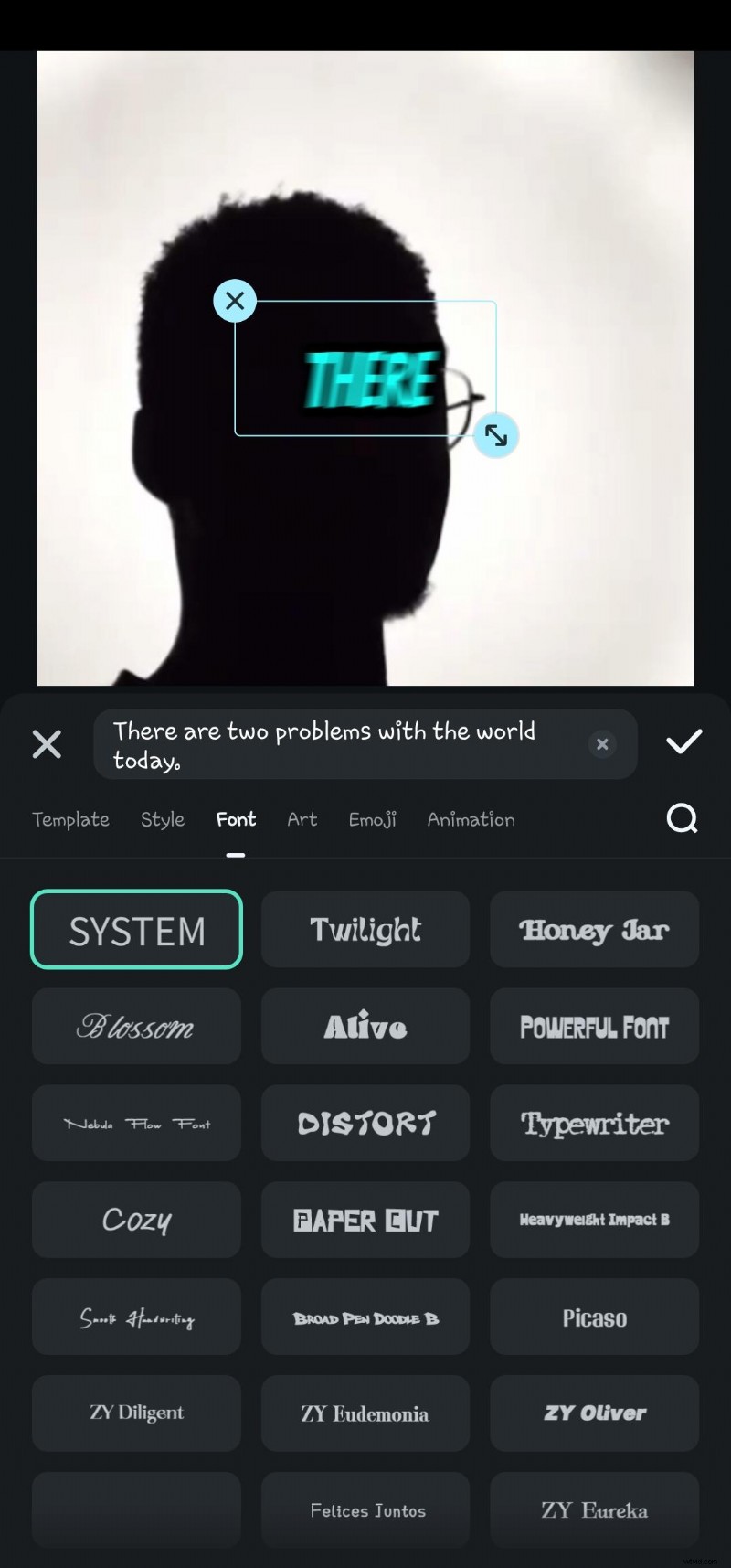
- Stap 6:Dubbelklik op de gegenereerde tekst in de tijdlijn om naar de optie spraak bewerken te navigeren. Hier kunt u animatie toevoegen, de tekstsjabloon, het lettertype, de stijl, de kunst, enz. wijzigen.
- Stap 7:Exporteer de video
Opmerking:U moet begrijpen dat Python-luidsprekerherkenning volledige controle geeft over modeltraining. Maar Filmora biedt een geautomatiseerde aanpak. De AI-functie zorgt voor efficiënte sprekerherkenning zonder de complexiteit van programmeren.
Deel 4:Waar kan ik apps voor sprekerherkenning gebruiken?

Sprekerherkenning in Python transformeert ongetwijfeld diverse industrieën. Deze technologie biedt een snelle en betrouwbare manier om stemmen in video- of audiobestanden te identificeren. Het wordt een fundamenteel onderdeel van verschillende industrieën. Hieronder vindt u de gebieden waar deze apps van toepassing zijn.
- Slimme assistenten en spraakgestuurde apparaten. Apps zoals Siri, Alexa en Google Assistant gebruiken luidsprekeridentificatie om stemmen te onderscheiden. Dit maakt gepersonaliseerde reacties, beveiligde toegang en aangepaste spraakopdrachten voor verschillende gebruikers mogelijk.
- Beveiliging en stemauthenticatie. Veel bedrijven gebruiken sprekeridentificatie om gebruikers te verifiëren en fraude te voorkomen. Het elimineert de wachtwoordafhankelijkheid en verbetert tegelijkertijd de gegevensbescherming en het gebruikersgemak.
- AI-aangedreven transcriptie en notulen van vergaderingen. Luidsprekerherkenning helpt toepassingen zoals Otter.ai sprekers te onderscheiden. Dit verhoogt de nauwkeurigheid van de transcriptie, vooral die met meerdere gesproken notities.
- Callcenters en klantenondersteuning. Callcenters gebruiken sprekerherkenning in Python om klantauthenticatie en -detectie te verbeteren. Door AI aangedreven systemen identificeren bellers met hun stem, waardoor er minder handmatige identiteitsverificatie nodig is. Dit verbetert de veiligheid, efficiëntie en responstijden van de klantenservice.
- Zorg en toegankelijkheid. Ziekenhuizen en zorgapps gebruiken luidsprekeridentificatie voor veilige patiëntauthenticatie. Op spraak gebaseerde AI-tools helpen personen met beperkte mobiliteit toegang te krijgen tot apparaten zonder fysieke interactie. Python-luidsprekerherkenning zorgt voor veilige medische toegang en verbetert de patiëntenzorg.
Conclusie
Python is een van de meest populaire talen voor spreker- en stemidentificatie. Het biedt krachtige bibliotheken zoals SpeechRecognition, PyAudio, Librosa en Pico Voice Eagle SDK.
Deze tools maken een hoge nauwkeurigheid en real-time sprekeridentificatie in Python mogelijk . Dit maakt het de beste optie voor ontwikkelaars, AI-onderzoekers en beveiligingstoepassingen. Filmora biedt een eenvoudiger alternatief voor mensen zonder programmeervaardigheden. Het biedt spraak-naar-tekst-conversie, stembewerking en sprekerherkenning zonder dat Python-codering nodig is.
Probeer de AI-aangedreven tools van Filmora voor automatische stembewerking en transcriptie. Ze maken het proces snel en vriendelijk.

Filmora
⭐⭐⭐⭐⭐
De beste AI-aangedreven videobewerkingssoftware en app