Google is officieel begonnen met het genereren van AI-video's met de lancering van Veo 3. Google Veo 3 is een nieuwe AI-videogenerator die tekstprompts omzet in korte video's van hoge kwaliteit. Het is gebouwd voor videomakers, docenten en marketeers en biedt geavanceerde weergave van scènes, vloeiende bewegingen en bediening van meerdere opnamen, allemaal mogelijk gemaakt door het nieuwste generatieve model van Google.
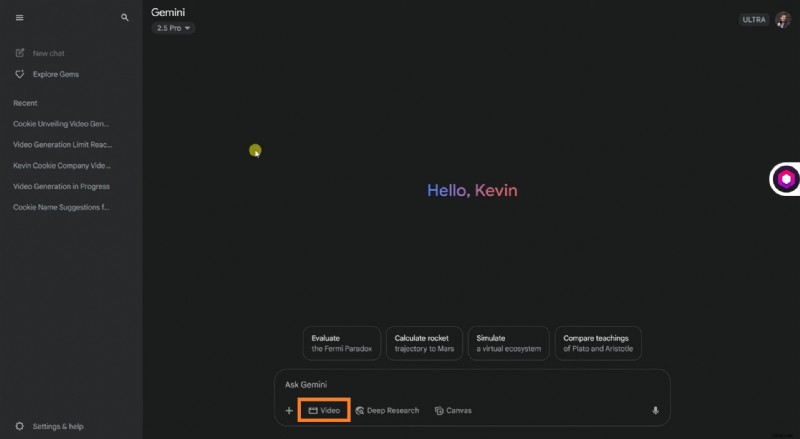
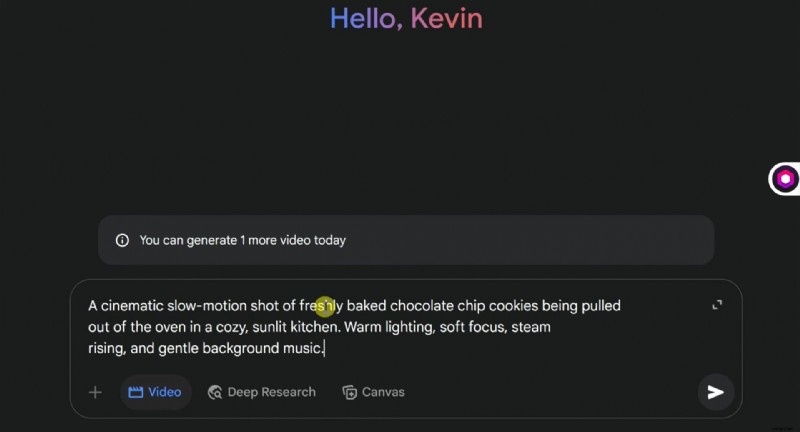
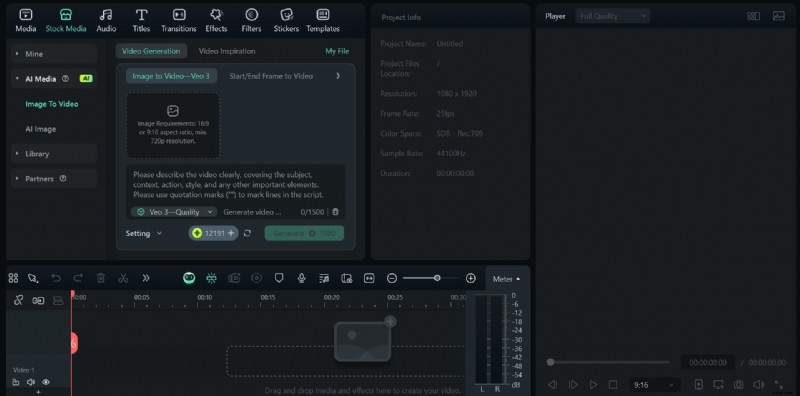
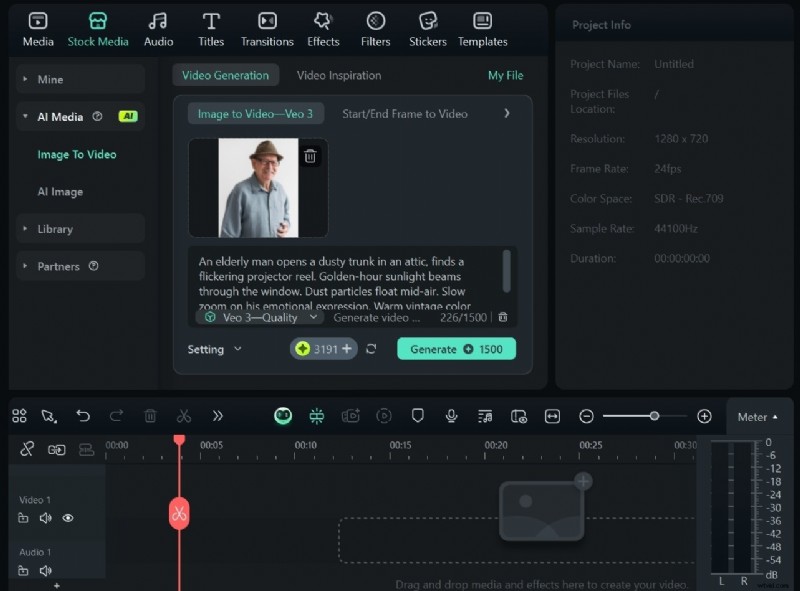
In deze handleiding wordt beschreven hoe u Google Veo 3 AI effectief kunt openen en gebruiken. Hier leert u het stapsgewijze proces kennen, ziet u in welke scenario's het het beste past, zoals in marketing of onderwijs, en begrijpt u de huidige beperkingen ervan. Als Veo 3 nog niet voor u beschikbaar is, laten we u ook zien hoe u vergelijkbare resultaten kunt verkrijgen met een nog geavanceerdere tool. Blijf lezen voor meer informatie.

In dit artikel
- Een kort overzicht van het Google Veo 3 AI-model
- Hoe u Google Veo 3 kunt openen en gebruiken
- Stapsgewijze handleiding voor het gebruik van de nieuwe AI-videogenerator van Google
- Genereer en bewerk video's met deze geavanceerde Veo-geïntegreerde video-editor
Een kort overzicht van het Google Veo 3 AI-model
Google Veo 3 markeert de ambitieuze intrede van de technologiegigant in de generatieve video-arena. In tegenstelling tot eenvoudige tekst-naar-video-tools maakt Veo 3 gebruik van het baanbrekende onderzoek van Google DeepMind om filmische video's met hoge definitie (1080p+) te produceren op basis van tekstprompts, inclusief Veo 3-prompts zoals gestructureerde scènebeschrijvingen, camerabewegingen, visuele stijlen en emotionele tonen, waardoor variabele opnamelengtes en complexe scène-overgangen worden ondersteund.

Kernfuncties van Google Veo 3
- Hoogwaardige videogeneratie
- Genereert video's met een resolutie van 1080p+ en filmische framesnelheden (24-60 FPS).
- Ondersteunt langere duur (mogelijk meer dan 60 seconden) met temporele consistentie.
- Audiovisuele synchronisatie
- Lipsynchronisatie:realistische mondbewegingen afgestemd op spraak (bijvoorbeeld voor virtuele avatars).
- Geluidseffecten:dynamische afstemming van audio (bijvoorbeeld voetstappen, explosies) met beelden.
- Multimodale invoer
- Accepteert tekst + audio + beeldprompts (bijvoorbeeld "een kat die danst" + muzieknummer).
- Fijnkorrelige controle over camerahoeken, belichting en stijlen.
- Inzicht in 3D-scènes
- Simuleert natuurkunde (zwaartekracht, botsingen) en dieptebewuste weergave.
- Behoudt objectduurzaamheid (geen "glitching" in langere clips).
- Efficiënt bewerken
- Wijzigt bestaande video's via tekst-/spraakopdrachten (bijvoorbeeld "verander de achtergrond naar Mars").
Belangrijke technische innovaties
| Innovatie | Hoe het werkt | Waarom het ertoe doet | ||
| Diffusietransformator (DiT) | Combineert diffusiemodellen met transformatoren voor schaalbare video met hoge resolutie. | Maakt langere, coherentere video's mogelijk. | ||
| Ruimte-Tijd U-Net | Verwerkt video in ruimtelijke en temporele blokken om flikkering te verminderen. | Vloeiendere frame-overgangen. | ||
| Cross-modaal contrastief leren | Lijnt audio, tekst en video uit in een gedeelde latente ruimte (zoals CLIP). | Nauwkeurige audiovisuele synchronisatie. | ||
| Neurale weergave | Incorporeert 3D-bewuste diffusie (vergelijkbaar met NeRF). | Realistische licht-/schaduweffecten. | ||
| RLHF voor synchronisatie | Gebruikt versterkend leren om de audiovisuele timing te verfijnen. | Elimineert vertragingen bij lipsynchronisatie. |
| Functie | Google Veo 3 | OpenAI Sora | Baan Gen-2 | Pika Labs |
| Maximale resolutie | 1080p+ | 1080p | 720p | 1080p |
| Audiosynchronisatie | ✅ Native | ❌ Geen | ❌ Handmatig bewerken | ❌ Geen |
| 3D-bewustzijn | ✅ Op natuurkunde gebaseerd | ✅ Basis | ❌ Beperkt | ❌ Beperkt |
| Invoermodaliteiten | Tekst + Audio + Afbeelding | Alleen tekst | Tekst + Afbeelding | Tekst + Afbeelding |
| Bewerkingsmogelijkheden | ✅ Geavanceerd | ❌ Nee | ✅ Basis | ✅ Basis |