
Bent u urenlang bezig met het verfijnen van videoverhalen? Met moderne door AI aangedreven tekst-naar-spraakconverters (TTS) kunt u elk geschreven script binnen enkele minuten omzetten in natuurlijk klinkende spraak, met uw eigen stem of een stemmodel van uw voorkeur.
Van podcasts tot YouTube-video's, AI-gestuurde TTS kan u helpen sneller boeiende inhoud te creëren en een breder publiek te bereiken. In dit artikel leggen we uit hoe TTS en stemklonen werken, en begeleiden we u bij het omzetten van uw opnamen in een herbruikbaar AI-stemmodel.
Hoe tekst-naar-spraak en spraakklonen werken

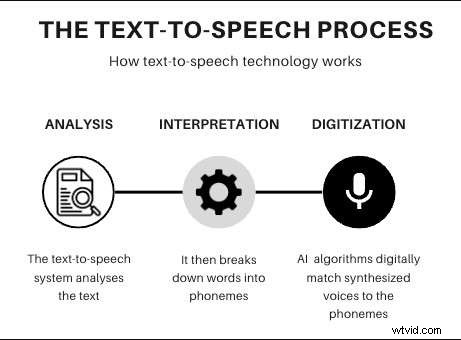
TTS-converters vertrouwen op diepe neurale netwerken die geschreven tekst analyseren, deze in fonemen opsplitsen en audiogolfvormen synthetiseren die natuurlijk en expressief klinken. Stemklonen daarentegen creëert een digitale tweeling van een specifieke stem door te trainen op een dataset van opgenomen spraak. Het resulterende model legt het unieke timbre, de cadans en de emotionele nuance van de oorspronkelijke spreker vast.
Beide technologieën delen dezelfde kern-AI-algoritmen (tekst-naar-audio en audio-naar-tekst), waardoor ze spraak in meerdere talen kunnen genereren en parameters zoals volume, snelheid en toonhoogte kunnen aanpassen.
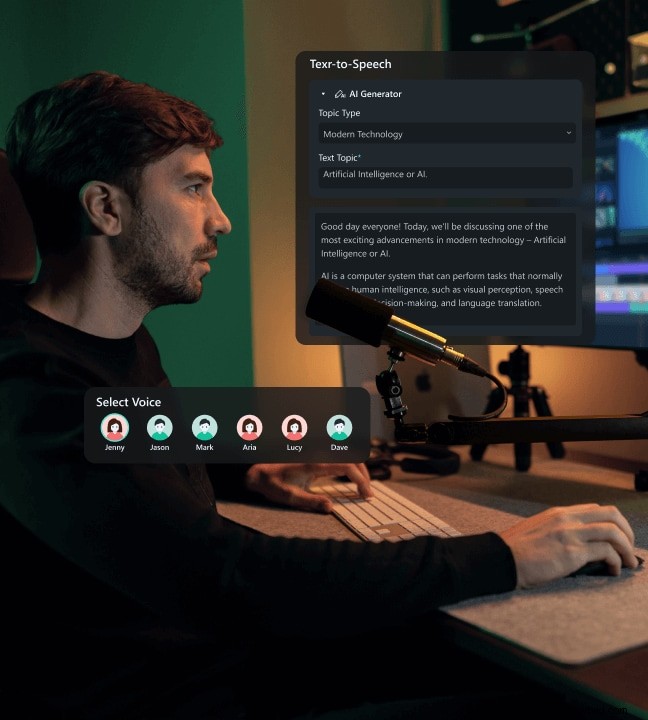
Met deze tools kunt u de stemuitvoer aanpassen aan elke merk- of creatieve behoefte. In de volgende secties wordt uitgelegd hoe u uw eigen stem kunt klonen en deze voor TTS kunt gebruiken.
Twee manieren om TTS te genereren met uw stem
1. Stemklonen – Neem een kort voorbeeld van uw stem op (meestal minder dan een minuut) en laat de AI de unieke kenmerken leren. Het resulterende model kan vervolgens elke door u opgegeven tekst uitspreken.
2. Standaard TTS – Gebruik een reeds bestaand stemmodel om tekst in spraak om te zetten. Deze methode vereist geen stemvoorbeeld, maar biedt minder personalisatie.
Hoewel beide benaderingen synthetische spraak produceren, zorgt stemklonen ervoor dat uw natuurlijke stem beter aansluit, waardoor de authenticiteit en de verbinding met het publiek worden verbeterd.
Genereer TTS in meerdere talen

Taalbarrières vormen een groot obstakel in de mondiale communicatie. Moderne TTS-platforms ondersteunen meer dan 30 talen, waardoor vertaling in realtime en meertalige vertelling mogelijk zijn. Door gebruik te maken van AI-stemmodellen kunt u inhoud voor diverse doelgroepen lokaliseren zonder extra stemtalent in te huren.
Stap voor stap:maak een AI-stemmodel met Wondershare Filmora
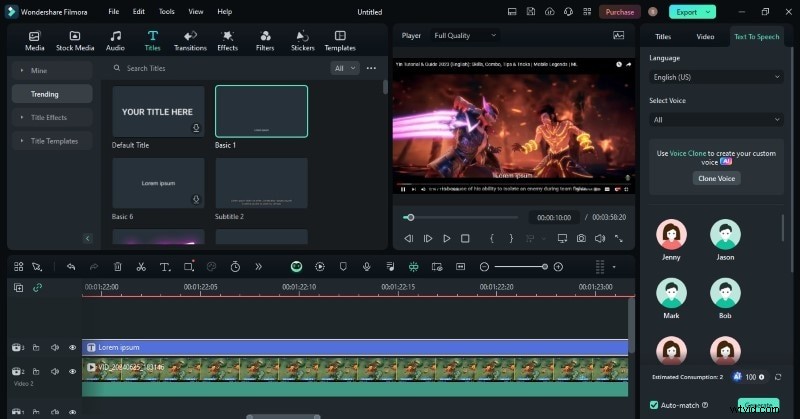
Wondershare Filmora is een uitgebreide video-editor die AI-copywriting, stemklonen en TTS integreert. Volg deze stappen om van uw opnamen een AI-stemmodel te maken en dit te gebruiken om commentaar te genereren.
- Stap 1: Start Filmora en importeer uw video. Sleep de clip naar de tijdlijn en open vervolgens de Titels tabblad.
- Stap 2: Selecteer een titelvoorinstelling, sleep deze naar de tijdlijn en klik op het titelnummer om de Eigenschappen te openen paneel.
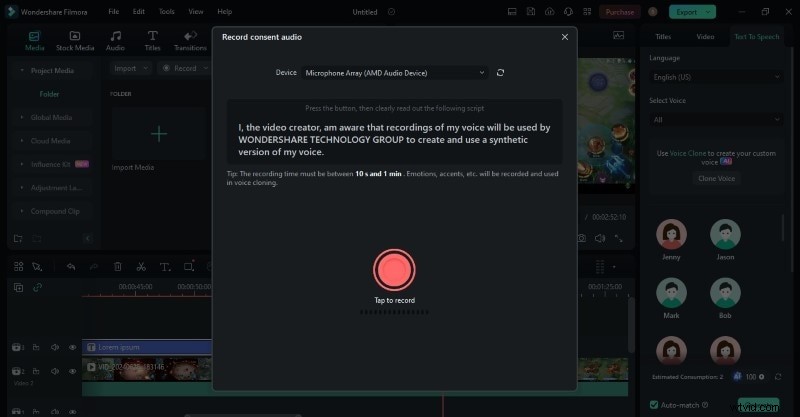
- Stap 3: In de Tekst-naar-spraak sectie, klik op Stem klonen . Sluit uw microfoon aan, tik vervolgens op "Opnemen" en lees het script dat u wilt klonen. Houd de opname korter dan een minuut voor een optimaal resultaat.
- Stap 4: Zodra het model is gemaakt, kiest u het uit de stemmenlijst, plakt u uw script in het tekstvak en klikt u op Genereren . De AI produceert een voice-over die overeenkomt met uw oorspronkelijke toon.
Conclusie
Door AI-gestuurde TTS en stemklonen te gebruiken, kunt u alle geschreven inhoud binnen enkele minuten omzetten in een professionele, gepersonaliseerde voice-over. De alles-in-één oplossing van Filmora, die spraakgeneratie, TTS en AI-copywriting combineert, maakt het eenvoudig om meertalige audio van hoge kwaliteit te creëren voor tutorials, podcasts, productdemo's en meer.
Met Filmora hoef je nooit meer urenlang een voice-over op te nemen of te bewerken. Laat de AI het zware werk doen, zodat jij je kunt concentreren op het leveren van boeiende verhalen.